Too large write data is pending: size=725124416, max_buffer_size=268435456 #4563
Comments
|
@vadnala You're hitting the limit on Chrome DevTools WebSocket: https://cs.chromium.org/chromium/src/content/browser/devtools/devtools_http_handler.cc?sq=package:chromium&g=0&l=83-84 In other words, DevTools protocol messages are limited to 256Mb in DevTools->Clients direction. The limit will go away once we teach Chromium to return PDFs as streams: https://crbug.com/748956 |
|
@aslushnikov Thanks for the reply and pointers. For time being (workaround), I am looking for an answer to either of these three
[0609/223146.069:ERROR:http_connection.cc(112)] Too large write data is pending: size=725124416, max_buffer_size=268435456 |
|
@vadnala the fix is already landing in chromium: https://chromium-review.googlesource.com/c/chromium/src/+/1652155 We'll have it in Puppeteer shortly (in a few days) and it will be available right away on npm as |
|
@aslushnikov That's great news and many thanks for the update. We have a customer issue and thus looking for a quick workaround. |
Unfortunately I can't think of any good way to handle this. The best you can rely upon is parsing the |
|
Any sample/example on how we can parse/capture "chrome" stdout / stderr from puppeteer? TIA |
This roll includes: - https://crrev.com/c/1652559 - inspector: fix queryObjects when page contains JSModuleNamespace - https://crrev.com/c/1649473 - [heapprofiler] QueryObjects: do not return objects retained by feedback information - https://crrev.com/c/1652155 - DevTools: teach page.printToPDF to return IO::Stream References puppeteer#4563 Fix puppeteer#4545
This roll includes: - https://crrev.com/c/1652559 - inspector: fix queryObjects when page contains JSModuleNamespace - https://crrev.com/c/1649473 - [heapprofiler] QueryObjects: do not return objects retained by feedback information - https://crrev.com/c/1652155 - DevTools: teach page.printToPDF to return IO::Stream References #4563 Fix #4545
This lets transferring massive PDF files over the protocol. Fix puppeteer#4563
This lets transferring massive PDF files over the protocol. Fix #4563
Steps to reproduce
Tell us about your environment:
What steps will reproduce the problem?
When printing web pages that contains hundreds of images.
Even tried the "pipe" mode but no avail. If this is a limitation, is there a way to find the size of the write data as it is obviously printing the following statement on the console window
[0609/223146.069:ERROR:http_connection.cc(112)] Too large write data is pending: size=725124416, max_buffer_size=268435456
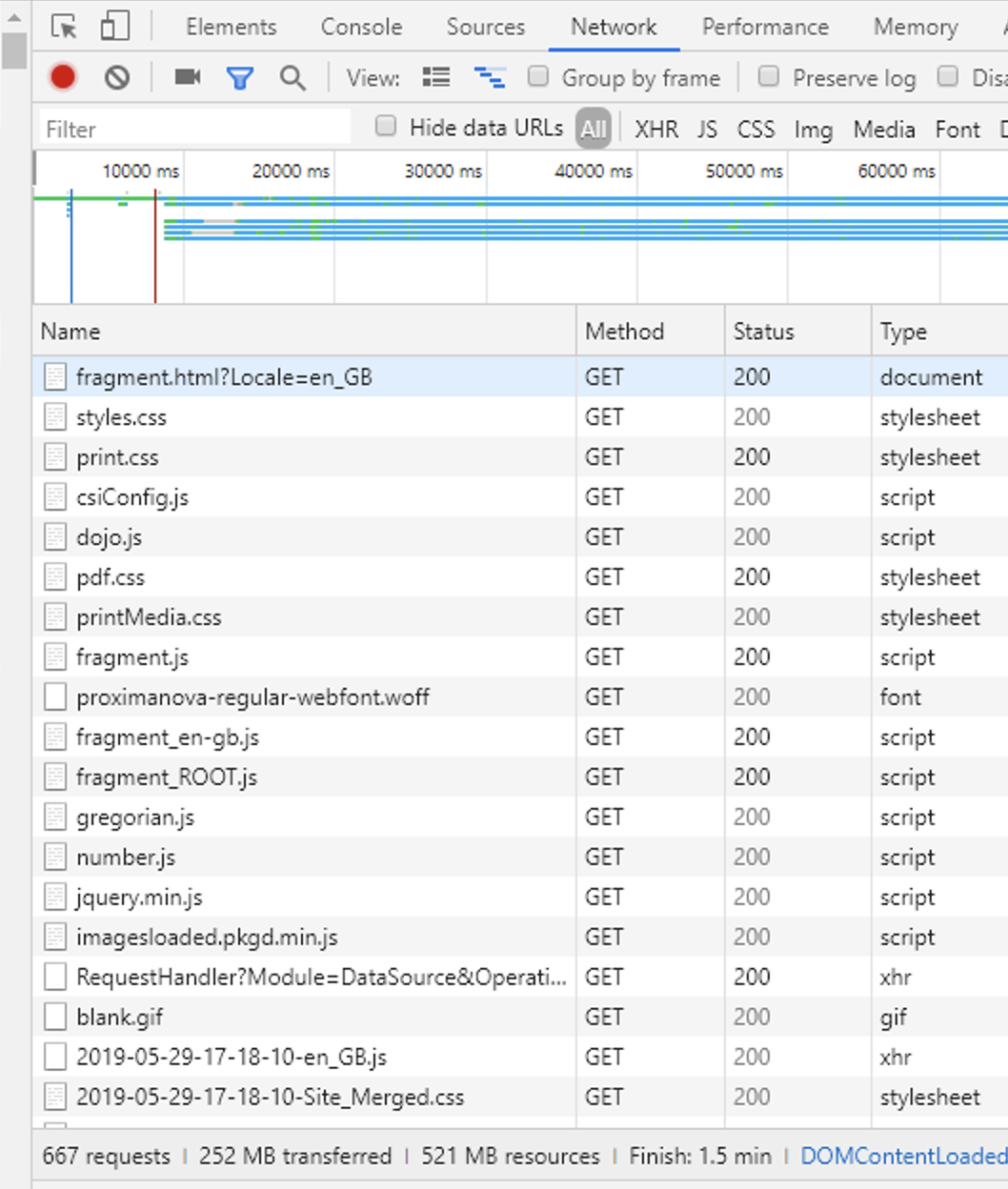
Tried Network.dataReceived option to read the data lengths to get to the overall size but the data size does not match. In my case, I got the data as 521 MB but the write data says 691 MB.
Attached a picture of the Network tab on the devTools. It says 521 MB resources which is correctly matching my reading. However, it says 252 MB transferred. How do I get this reading? Either way, how do I get the write data size?
What is the expected result?
Successfully generate the PDF irrespective of the size of the write data. Else, way to know the size of the write data so that we can document the known limitations.
What happens instead?
Fails to generate the PDF when the page contains of hundreds of images. In other words, when the write data is too large.
The text was updated successfully, but these errors were encountered: